

All courses have been completed successfully. We summarized the content of the 'Data Literacy in Genome Research' course, our experiences, and the applied didactic methods in a publication (Wolff et al., 2023). You can read it to learn additional details about the course completed by six cohorts. Please contact Boas Pucker and Katharina Wolff if you are interested. We are currently working to establish a permanent module to teach students data literacy.
This project is a teaching innovation that was funded by "Stiftung Innovation in der Hochschullehre" as part of "Freiraum2022".
Course content and concept:
Using the example of a plant genome sequencing, the students should plan and practically carry out all work steps of a real project. One focus here is on the integrated teaching of content from different subjects, including biochemistry, molecular biology, genomics and bioinformatics. The project begins with compliance with legal requirements such as the Nagoya Protocol when selecting samples. In addition, the students learn how to combine information from various sources in order to optimally plan their project. They will then plan their work steps in the laboratory to extract high molecular weight DNA and perform sequencing using nanopore technology (MinION). A particular challenge is the efficient utilization of the sequencing capacities. The students assume responsibility for valuable equipment and materials. Molecular biology laboratories and equipment are provided by the Plant Biotechnology and Bioinformatics group. All work steps are documented by the students in a digital laboratory book. The students should mutually review their documentation and make suggestions for improvements (peer review). This sharpens the understanding of important details in the metadata through cooperative learning. I have already had good experiences with digital laboratory notebooks and peer review for protocol control in a project funded by the Stifterverband. Another innovative element of this project is the presentation of progress via social media. The aim is to acquire initial skills for science communication. The planned sequencing will generate large datasets, so students will gain experience in handling large datasets. These data sets are to be processed, whereby an exact documentation of all steps is essential. A cloud-based solution is to be used for the analyzes in order to show current developments in bioinformatics. The students learn to find reliable backup solutions in order to avoid the loss of data sets. Finally, the final datasets are to be published via the established repositories. This includes the European Nucleotide Archive for the sequencing data. A precise description of the sequencing process is necessary. In this context, the students should internalize the concept of FAIR (Findable Accessible Interoperable Reuseable) data. Different options for the publication of datasets should be compared by the students with regard to their advantages and disadvantages. At the end of the event, the students should present their results to an international audience in a self-organized online conference.
Learning objectives:
Students should be able to independently plan, implement and fully document data-intensive projects (data literacy); plan and carry out genome sequencing projects and other omics projects independently; analyze large datasets cloud-based and publish their results; present their work and its results to an interested public and a specialist audience.
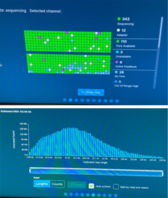
Here are some impressions of the first "Data Literacy in Genome Research" course.




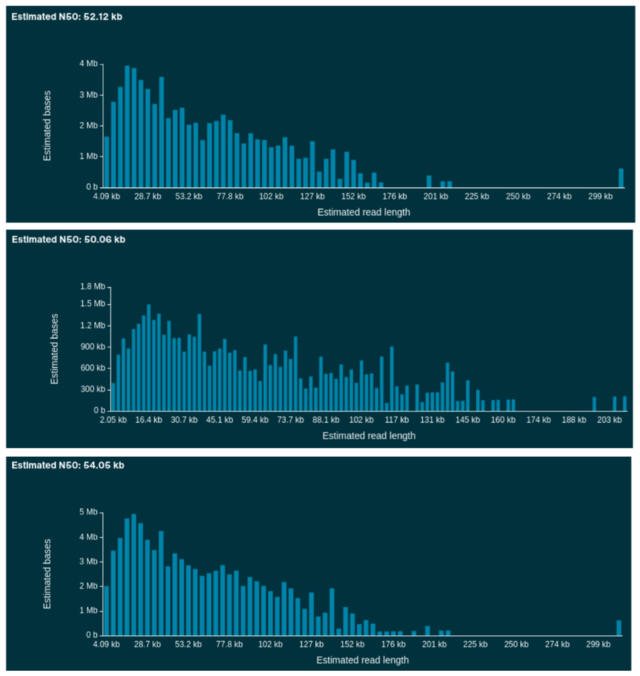





Teaching materials of the lecutre are freely available on GitHub (Data Literacy in Genome Research). Reuse in other courses (with proper credit) is encouraged. Our protocols for the wet lab part of this course are freely available via protocols.io: "Plant DNA extraction and preparation for ONT sequencing".
We described the technology, the recent progress in the research field and future developments in a review article: "Plant genome sequence assembly in the era of long reads: Progress, challenges and future directions"